NumPy で「n次元配列」を「1次元配列」に変換するときに ravel() 関数と flatten() 関数がサポートされている.ravel() 関数に関しては,正確には numpy.ravel() 関数と numpy.ndarray.ravel() 関数がある.それぞれの違いを整理するためにドキュメントを読みながら試してみた.今回は Numpy 1.20.2 を前提にする.
- numpy.ravel — NumPy v1.20 Manual
- numpy.ndarray.ravel — NumPy v1.20 Manual
- numpy.ndarray.flatten — NumPy v1.20 Manual
簡単に違いを整理しておくと,ravel() 関数は基本的には「参照」を返して,flatten() 関数は「コピー」を返す.パフォーマンスにも差がある.個人的には flatten という単語は Ruby で見たことがあるけど,ravel という単語は見たことがなかった!調べてみたら「ほぐす」や「ほどく」という意味だった.なるほどー💡
ravel() 関数を試す 🔢
まず,ravel() 関数(正確には numpy.ndarray.ravel() 関数)を試す.以下のように 3x3 の配列 base_array を作り,ravel() 関数を使うと,配列 ravel_array の結果の通り「1次元配列」に変換できた.
import numpy as np base_array = np.array( [ [1, 2, 3], [4, 5, 6], [7, 8, 9] ] ) base_array # array([[1, 2, 3], # [4, 5, 6], # [7, 8, 9]]) ravel_array = base_array.ravel() ravel_array # array([1, 2, 3, 4, 5, 6, 7, 8, 9])

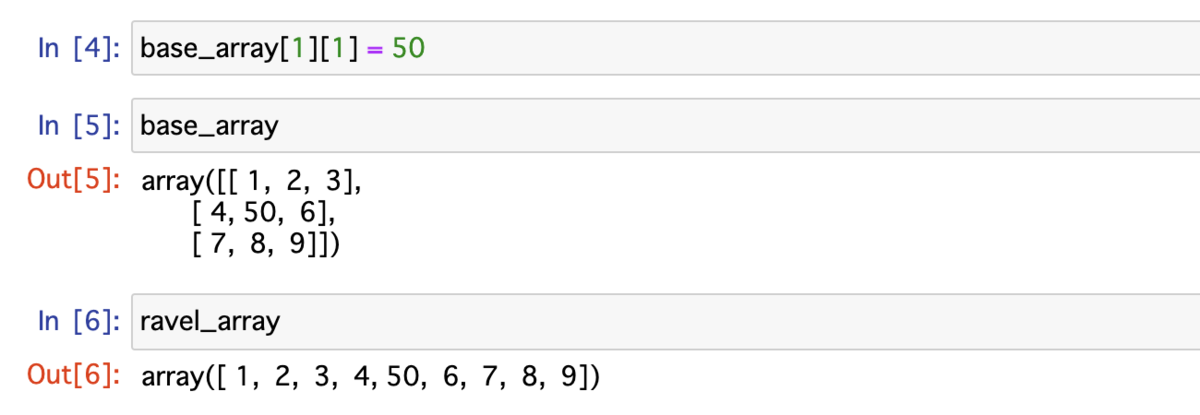
次に配列 base_array の値を更新する.すると,配列 ravel_array の値も更新されていた.ravel() 関数は基本的には「参照」を返すため,配列 base_array だけではなく,配列 ravel_array にも影響する.なお,あえて「基本的には」と書いたのはドキュメントに以下のように書いてあるため.
A 1-D array, containing the elements of the input, is returned. A copy is made only if needed.
base_array[1][1] = 50 base_array # array([[ 1, 2, 3], # [ 4, 50, 6], # [ 7, 8, 9]]) ravel_array # array([ 1, 2, 3, 4, 50, 6, 7, 8, 9])
flatten() 関数を試す 🔢
次に flatten() 関数(正確には numpy.ndarray.flatten() 関数)を試す.同じく 3x3 の配列 base_array を作り,flatten() 関数を使うと,配列 flatten_array の結果の通り「1次元配列」に変換できた.ここまでは ravel() 関数と同じ挙動になる.
base_array = np.array(
[
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]
)
base_array
# array([[1, 2, 3],
# [4, 5, 6],
# [7, 8, 9]])
flatten_array = base_array.flatten()
flatten_array
# array([1, 2, 3, 4, 5, 6, 7, 8, 9])

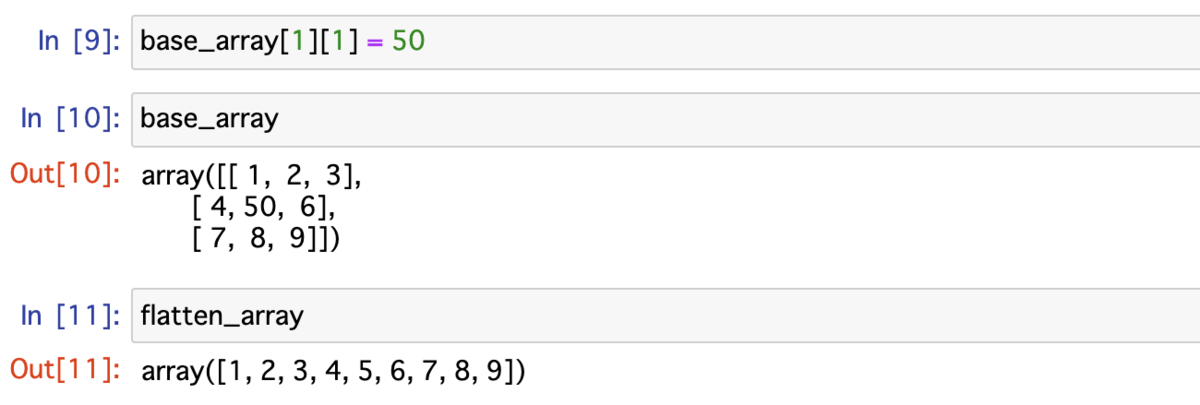
同じく配列 base_array の値を更新する.すると,配列 flatten_array の値は更新されていなかった.flatten() 関数は「コピー」を返すため,配列 flatten_array には影響しなかった.ドキュメントに以下のように書いてある.
Return a copy of the array collapsed into one dimension.
base_array[1][1] = 50 base_array # array([[ 1, 2, 3], # [ 4, 50, 6], # [ 7, 8, 9]]) flatten_array # array([1, 2, 3, 4, 5, 6, 7, 8, 9])
ravel() 関数と flatten() 関数の実行時間を比較する 🔢
最後は Jupyter Notebook の %%timeit マジックコマンドを使って,ravel() 関数と flatten() 関数の実行時間を比較する.実行環境によって結果に差が出るため,あくまで MacBook Pro で計測したサンプル値として確認してもらえればと🙏
結果としては以下の通り,ある程度差が出る.flatten() 関数は相対的に遅く,「コピー」を返すためにメモリも多く消費するため,アプリケーション目線で用途によって使い分けるのが良さそう.
%%timeit base_array.ravel() # 152 ns ± 0.719 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each) %%timeit base_array.flatten() # 560 ns ± 7.72 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)

まとめ 🔢
Pandas に続き,今度は NumPy の機能を学んでいる.今回は NumPy で「n次元配列」を「1次元配列」に変換できる ravel() 関数と flatten() 関数を試しつつ,機能の違いも確認した.
- numpy.ravel — NumPy v1.20 Manual
- numpy.ndarray.ravel — NumPy v1.20 Manual
- numpy.ndarray.flatten — NumPy v1.20 Manual





















