
Kubernetes を使っていると,運用面で起動中の Pod を他のノードに移動(再スケジューリング)したくなる場面がある.以下に具体的な例を挙げる.理由としては,Kubernetes では kube-scheduler によって Pod を起動する前にノードが決まる仕組み(スケジューリング)になっている.よって,スケジューリング後の Pod は再スケジューリングされず,起動され続けることになる.
- ノードを追加した後に起動中の Pod を移動したい
- 一部ノードの使用率が高いので起動中の Pod を移動したい
- 後からノードに taint を追加したから条件に合わない Pod を移動したい
Descheduler for Kubernetes 🧩
今回紹介する「Descheduler for Kubernetes」を使うと,設定した「戦略」によって起動中の Pod を再スケジューリングする仕組みを Kubernetes クラスタに導入できる.正確に言うと「Descheduler」によって Pod が「再スケジューリング」されるのではなく,「Descheduler」によって「Eviction(排出)」された Pod が kube-scheduler によって「再スケジューリング」される.
github.com
セットアップ 🧩
Quick Start を読むと複数のセットアップ方法が紹介されている.今回は Helm を使う.Helm を使うとデフォルトでは CronJob で Descheduler が起動されるけど,設定によって Deployment も選べるようになっている.
- Run As A Job
- Run As A CronJob
- Run As A Deployment
- Install Using Helm
- Install Using Kustomize
手順は Artifact Hub に載っている.helm install コマンドを実行すれば簡単にセットアップできる.ConfigMap を確認すると,デフォルトでは以下の5個の「戦略」が有効化されていた.戦略に関しては後述する!
LowNodeUtilizationRemoveDuplicatesRemovePodsViolatingInterPodAntiAffinityRemovePodsViolatingNodeAffinityRemovePodsViolatingNodeTaints
artifacthub.io
$ helm repo add descheduler https://kubernetes-sigs.github.io/descheduler/
$ helm install descheduler --namespace kube-system descheduler/descheduler
$ kubectl get cronjobs -n kube-system
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
descheduler */2 * * * * False 1 40s 45s
$ kubectl get configmaps -n kube-system descheduler -o yaml
apiVersion: v1
data:
policy.yaml: |
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
LowNodeUtilization:
enabled: true
params:
nodeResourceUtilizationThresholds:
targetThresholds:
cpu: 50
memory: 50
pods: 50
thresholds:
cpu: 20
memory: 20
pods: 20
RemoveDuplicates:
enabled: true
RemovePodsViolatingInterPodAntiAffinity:
enabled: true
RemovePodsViolatingNodeAffinity:
enabled: true
params:
nodeAffinityType:
- requiredDuringSchedulingIgnoredDuringExecution
RemovePodsViolatingNodeTaints:
enabled: true
kind: ConfigMap
(中略)
Descheduler 戦略 🧩
GitHub に載っているドキュメントを読むと非常に多機能で「戦略」だけでも「計10種類」ある.今回は RemovePodsViolatingTopologySpreadConstraint と PodLifeTime にフォーカスして紹介する.
RemoveDuplicatesLowNodeUtilizationHighNodeUtilizationRemovePodsViolatingInterPodAntiAffinityRemovePodsViolatingNodeAffinityRemovePodsViolatingNodeTaintsRemovePodsViolatingTopologySpreadConstraint ✅ 今回試すRemovePodsHavingTooManyRestartsPodLifeTime ✅ 今回試すRemoveFailedPods
検証環境 🧩
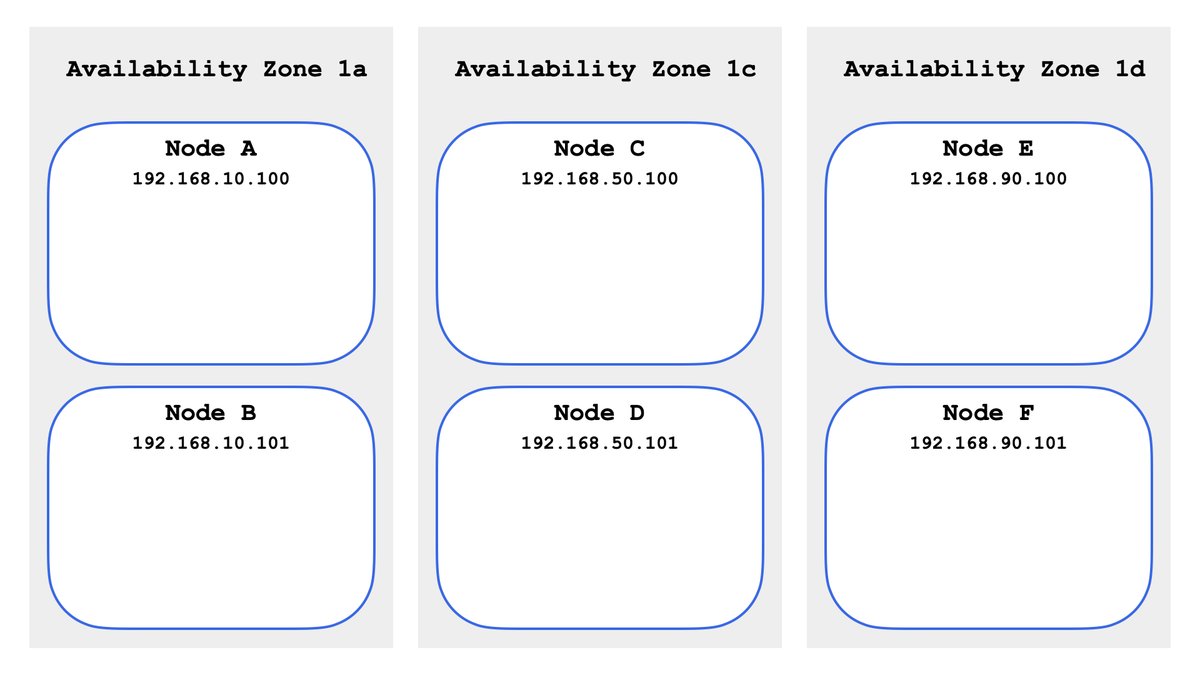
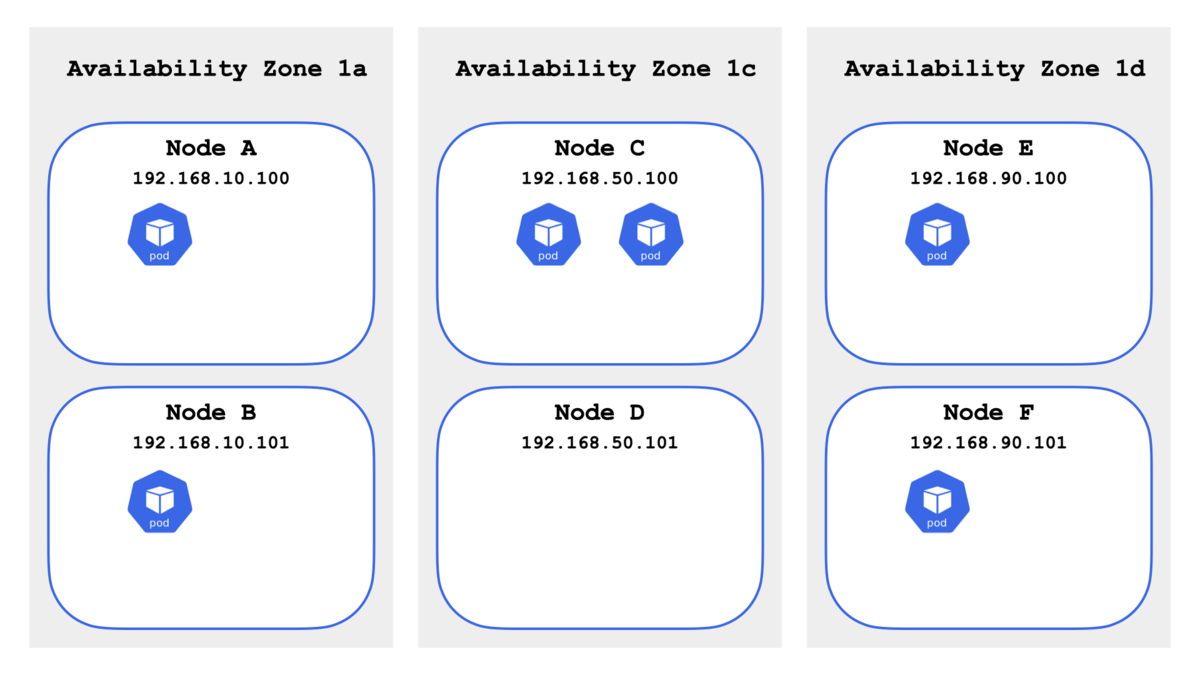
今回は検証環境として eksctl を使って構築した Amazon EKS クラスタ (Kubernetes 1.21) を使う.以下のように 3 Availability Zone に 6 ノードを構築してある.IP アドレスは説明のためにわかりやすく書き換えてある(第3オクテットを .10 / .50 / .90 に合わせた).
$ kubectl get nodes \
> -l 'eks.amazonaws.com/nodegroup=nodegroup' \
> -o=custom-columns=NAME:.metadata.name,ZONE:metadata.labels."topology\.kubernetes\.io/zone",STATUS:status.conditions[-1].type \
> --sort-by metadata.labels."topology\.kubernetes\.io/zone"
NAME ZONE STATUS
ip-192-168-10-100.ap-northeast-1.compute.internal ap-northeast-1a Ready
ip-192-168-10-101.ap-northeast-1.compute.internal ap-northeast-1a Ready
ip-192-168-50-100.ap-northeast-1.compute.internal ap-northeast-1c Ready
ip-192-168-50-101.ap-northeast-1.compute.internal ap-northeast-1c Ready
ip-192-168-90-100.ap-northeast-1.compute.internal ap-northeast-1d Ready
ip-192-168-90-101.ap-northeast-1.compute.internal ap-northeast-1d Ready
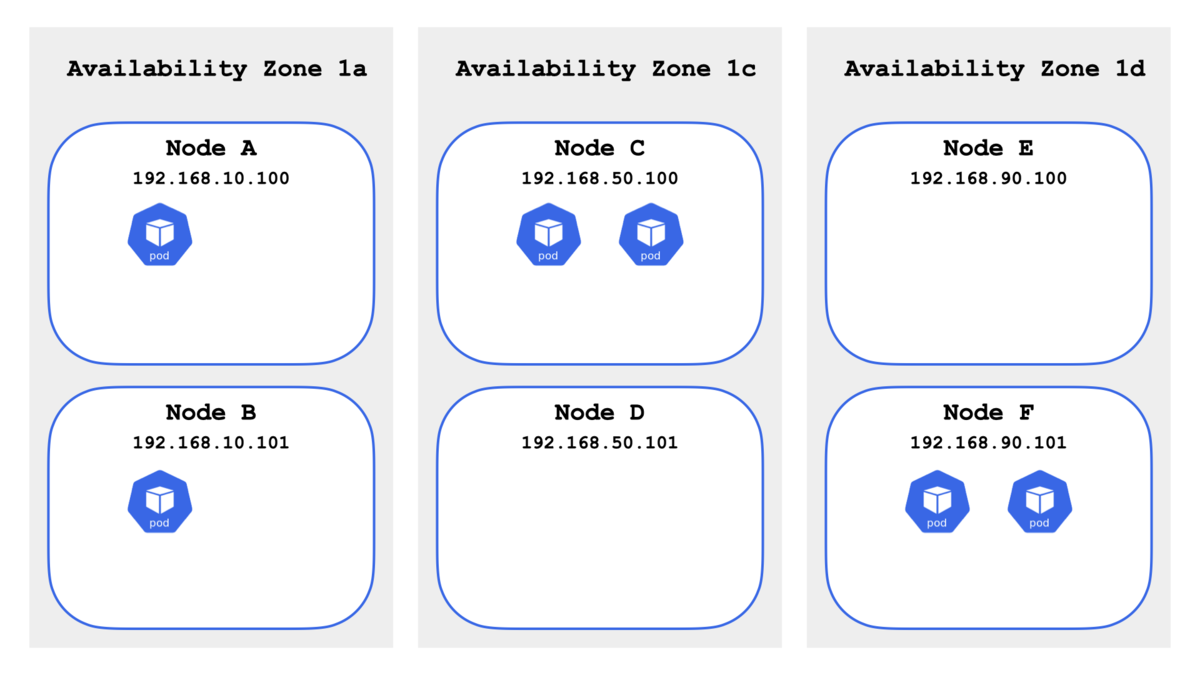
1. RemovePodsViolatingTopologySpreadConstraint
さっそく RemovePodsViolatingTopologySpreadConstraint を試す.これは「Pod Topology Spread Constraints」に違反している Pod を探して Eviction(排出)してくれる.「Pod Topology Spread Constraints」に関しては以下の記事にまとめてある.
kakakakakku.hatenablog.com
まず spec.topologySpreadConstraints を設定した Deployment で Pod を「6個」起動する.
apiVersion: apps/v1
kind: Deployment
metadata:
name: topology-spread-constraints
spec:
replicas: 6
selector:
matchLabels:
app: topology-spread-constraints
template:
metadata:
labels:
app: topology-spread-constraints
spec:
containers:
- name: nginx
image: nginx:1.21
ports:
- containerPort: 80
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: topology-spread-constraints
期待通りに各 Availability Zone に 2 Pod 起動している.
$ kubectl get pods \
> -o=custom-columns=NAME:.metadata.name,NODE:.spec.nodeName \
> -l app=topology-spread-constraints \
> --sort-by .spec.nodeName
NAME NODE
topology-spread-constraints-7bcb664dc6-b6wt4 ip-192-168-10-100.ap-northeast-1.compute.internal
topology-spread-constraints-7bcb664dc6-jlwrx ip-192-168-10-101.ap-northeast-1.compute.internal
topology-spread-constraints-7bcb664dc6-774lt ip-192-168-50-100.ap-northeast-1.compute.internal
topology-spread-constraints-7bcb664dc6-tk7rd ip-192-168-50-100.ap-northeast-1.compute.internal
topology-spread-constraints-7bcb664dc6-92fx8 ip-192-168-90-101.ap-northeast-1.compute.internal
topology-spread-constraints-7bcb664dc6-rt46n ip-192-168-90-101.ap-northeast-1.compute.internal
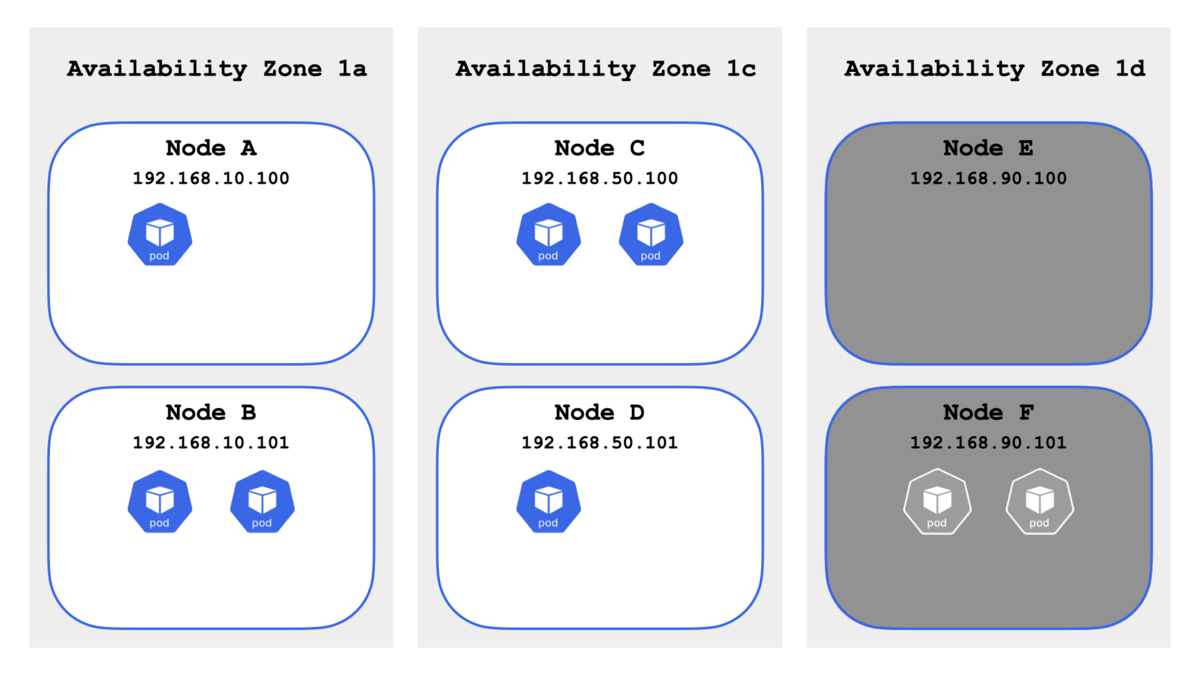
次に kubectl drain コマンドを使って Availability Zone 1d のノードを意図的にメンテナンスにする.kubectl drain コマンドに関しては以下の記事にまとめてある.
kakakakakku.hatenablog.com
$ kubectl drain ip-192-168-90-100.ap-northeast-1.compute.internal --ignore-daemonsets
$ kubectl drain ip-192-168-90-101.ap-northeast-1.compute.internal --ignore-daemonsets
結果的に 6 Pod は Availability Zone 1a と Availability Zone 1c に偏った.
$ kubectl get pods \
> -o=custom-columns=NAME:.metadata.name,NODE:.spec.nodeName \
> -l app=topology-spread-constraints \
> --sort-by .spec.nodeName
NAME NODE
topology-spread-constraints-7bcb664dc6-b6wt4 ip-192-168-10-100.ap-northeast-1.compute.internal
topology-spread-constraints-7bcb664dc6-jlwrx ip-192-168-10-101.ap-northeast-1.compute.internal
topology-spread-constraints-7bcb664dc6-l77cf ip-192-168-10-101.ap-northeast-1.compute.internal
topology-spread-constraints-7bcb664dc6-nmwpd ip-192-168-50-100.ap-northeast-1.compute.internal
topology-spread-constraints-7bcb664dc6-774lt ip-192-168-50-100.ap-northeast-1.compute.internal
topology-spread-constraints-7bcb664dc6-tk7rd ip-192-168-50-101.ap-northeast-1.compute.internal
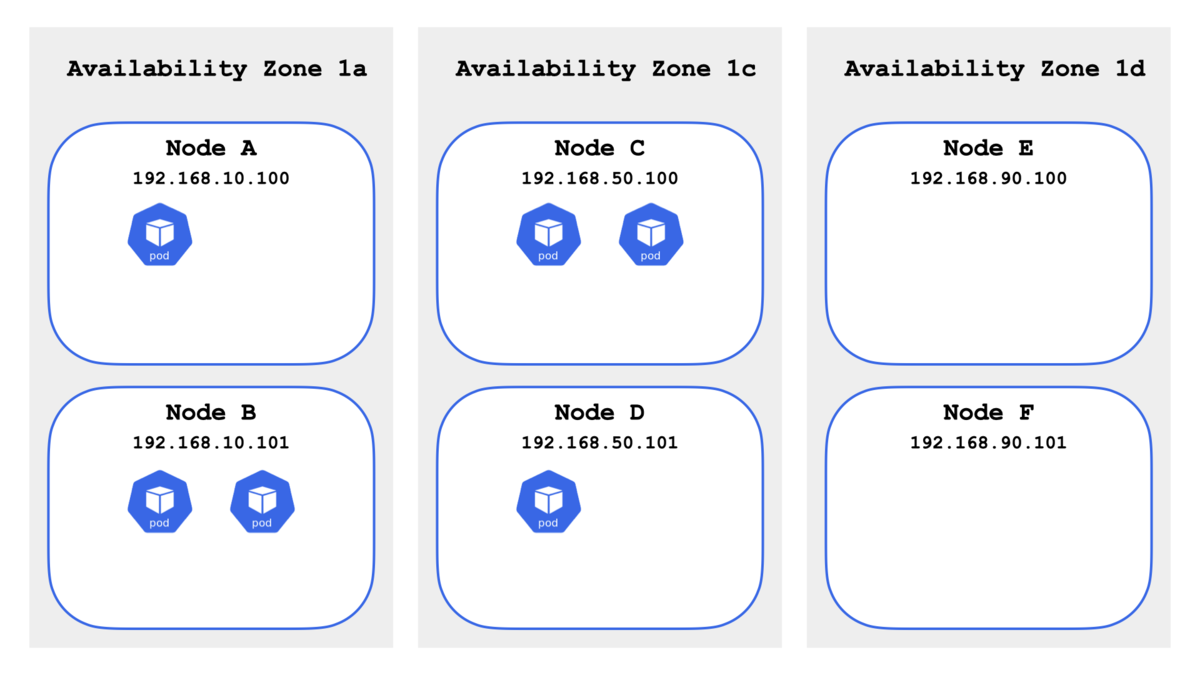
次にメンテナンスを完了したことにして Availability Zone 1d のノードを kubectl uncordon コマンドを使って戻す.しかし,起動中の Pod は移動されずそのままになるため,Availability Zone 1d のノードにスケジューリングされずに「偏ったまま」となる.
$ kubectl uncordon ip-192-168-87-26.ap-northeast-1.compute.internal
$ kubectl uncordon ip-192-168-70-254.ap-northeast-1.compute.internal
$ kubectl get pods \
> -o=custom-columns=NAME:.metadata.name,NODE:.spec.nodeName \
> -l app=topology-spread-constraints \
> --sort-by .spec.nodeName
NAME NODE
topology-spread-constraints-7bcb664dc6-b6wt4 ip-192-168-10-100.ap-northeast-1.compute.internal
topology-spread-constraints-7bcb664dc6-jlwrx ip-192-168-10-101.ap-northeast-1.compute.internal
topology-spread-constraints-7bcb664dc6-l77cf ip-192-168-10-101.ap-northeast-1.compute.internal
topology-spread-constraints-7bcb664dc6-nmwpd ip-192-168-50-100.ap-northeast-1.compute.internal
topology-spread-constraints-7bcb664dc6-774lt ip-192-168-50-100.ap-northeast-1.compute.internal
topology-spread-constraints-7bcb664dc6-tk7rd ip-192-168-50-101.ap-northeast-1.compute.internal
前置きが長くなった!やっとここで「Descheduler」の本領発揮となる.まずは RemovePodsViolatingTopologySpreadConstraint を有効化するために ConfigMap を以下のように更新する.
apiVersion: v1
data:
policy.yaml: |
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
RemovePodsViolatingTopologySpreadConstraint:
enabled: true
params:
includeSoftConstraints: true
kind: ConfigMap
(中略)
少し待つと(Descheduler のデフォルト設定では 2 min 間隔)Pod が再スケジューリングされた.おおー👏
$ kubectl get pods \
> -o=custom-columns=NAME:.metadata.name,NODE:.spec.nodeName \
> -l app=topology-spread-constraints \
> --sort-by .spec.nodeName
NAME NODE
topology-spread-constraints-7bcb664dc6-b6wt4 ip-192-168-10-100.ap-northeast-1.compute.internal
topology-spread-constraints-7bcb664dc6-jlwrx ip-192-168-10-101.ap-northeast-1.compute.internal
topology-spread-constraints-7bcb664dc6-nmwpd ip-192-168-50-100.ap-northeast-1.compute.internal
topology-spread-constraints-7bcb664dc6-774lt ip-192-168-50-100.ap-northeast-1.compute.internal
topology-spread-constraints-7bcb664dc6-l74k2 ip-192-168-90-100.ap-northeast-1.compute.internal
topology-spread-constraints-7bcb664dc6-d7tfb ip-192-168-90-101.ap-northeast-1.compute.internal
2. PodLifeTime
今度は PodLifeTime を試す.これは設定した「Pod の起動時間上限」に違反している Pod を探して Eviction(排出)してくれる.継続的に Pod を作り直してリフレッシュしたいときに使える.PodLifeTime を有効化するために ConfigMap を以下のように更新する.
podLifeTime.maxPodLifeTimeSeconds
matchLabels
$ kubectl get configmaps -n kube-system descheduler -o yaml
apiVersion: v1
data:
policy.yaml: |
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
PodLifeTime:
enabled: true
params:
podLifeTime:
maxPodLifeTimeSeconds: 300
matchLabels:
app: pod-life-time
kind: ConfigMap
(中略)
さっそく Deployment で Pod を「3個」起動する.
apiVersion: apps/v1
kind: Deployment
metadata:
name: pod-life-time
spec:
replicas: 3
selector:
matchLabels:
app: pod-life-time
template:
metadata:
labels:
app: pod-life-time
spec:
containers:
- name: nginx
image: nginx:1.21
ports:
- containerPort: 80
少し待つと Pod が作り直された.おおー👏
$ kubectl get pods -l app=pod-life-time
pod-life-time-5bf5bc8dcf-bqbwc 1/1 Running 0 24s
pod-life-time-5bf5bc8dcf-jc45x 1/1 Running 0 25s
pod-life-time-5bf5bc8dcf-n7xb5 1/1 Running 0 24s
$ kubectl get pods -l app=pod-life-time
pod-life-time-5bf5bc8dcf-bqbwc 1/1 Running 0 5m35s
pod-life-time-5bf5bc8dcf-jc45x 1/1 Running 0 5m36s
pod-life-time-5bf5bc8dcf-n7xb5 1/1 Running 0 5m35s
$ kubectl get pods -l app=pod-life-time
pod-life-time-5bf5bc8dcf-8pbbc 1/1 Running 0 18s
pod-life-time-5bf5bc8dcf-bbpnv 1/1 Running 0 17s
pod-life-time-5bf5bc8dcf-jzrlk 1/1 Running 0 18s
アンインストール 🧩
検証が終わったら Helm で削除しておく.
$ helm uninstall descheduler --namespace kube-system
release "descheduler" uninstalled
まとめ 🧩
今回は「Descheduler for Kubernetes」を試して,起動中の Pod を他のノードに移動(再スケジューリング)できることを確認した.記事では RemovePodsViolatingTopologySpreadConstraint と PodLifeTime にフォーカスしたけど,他にも LowNodeUtilization(使用率が低いノードを有効活用する)と RemovePodsViolatingNodeTaints(taint に違反する Pod を Eviction する)も試して,理解を深められた.Kubernetes クラスタの耐障害性などを考慮すると「Descheduler for Kubernetes」を導入すると良さそう!
github.com
![Software Design (ソフトウェアデザイン) 2022年04月号 [雑誌]](https://m.media-amazon.com/images/I/51lS2XfM6KL._SL500_.jpg "Software Design (ソフトウェアデザイン) 2022年04月号 [雑誌]")
")


