Kaggle が公開している「Kaggle Courses」 で機械学習に入門できる「Intro to Machine Learning」 コースを受講した.Intro と書いてある通り,入門レベルではあるけど,scikit-learn を使って「決定木(回帰)」 や「ランダムフォレスト」 で「住宅価格予測」 を体験できる.紹介も兼ねて,受講したメモを整理してまとめる!
www.kaggle.com
アジェンダ 🌴
「Intro to Machine Learning」 コースには「計7種類」 のレッスン(ドキュメントと演習)がある.なお,データを取り扱うときに Pandas の知識は最低限必要になるため,もし不安があれば,先に「Pandas」 コースを受講しておくと良いと思う.詳細は前にブログで紹介した.
How Models Work
Basic Data Exploration
Your First Machine Learning Model
Model Validation
Underfitting and Overfitting
Random Forests
Machine Learning Competitions
kakakakakku.hatenablog.com
1. How Models Work 🌴
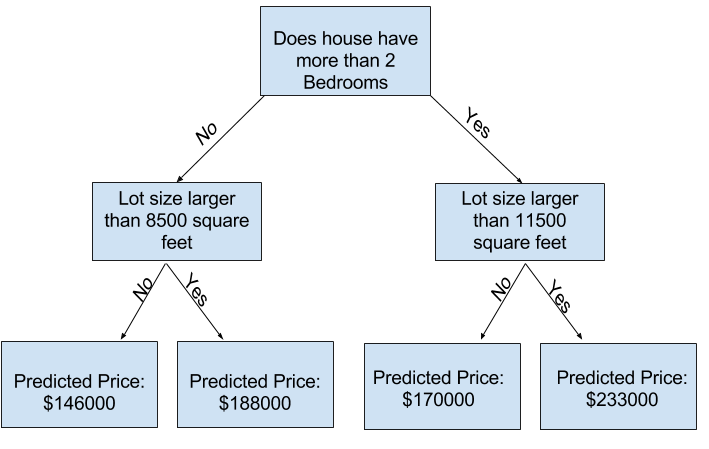
最初は今回テーマとする「住宅価格予測」 の概要と「決定木」 の紹介が載っている.例えば「寝室を2つ以上持っているかどうか」 という基準だと,一般的な傾向としては寝室が多い方が住宅価格は高いと予測できる.しかし,実際にはバスルームやロケーションなど,他にも様々な特徴を考慮する必要があり,それらを「決定木」 として,木構造で Yes/No に分岐していく.
How Models Work | Kaggle より引用
2. Basic Data Exploration 🌴
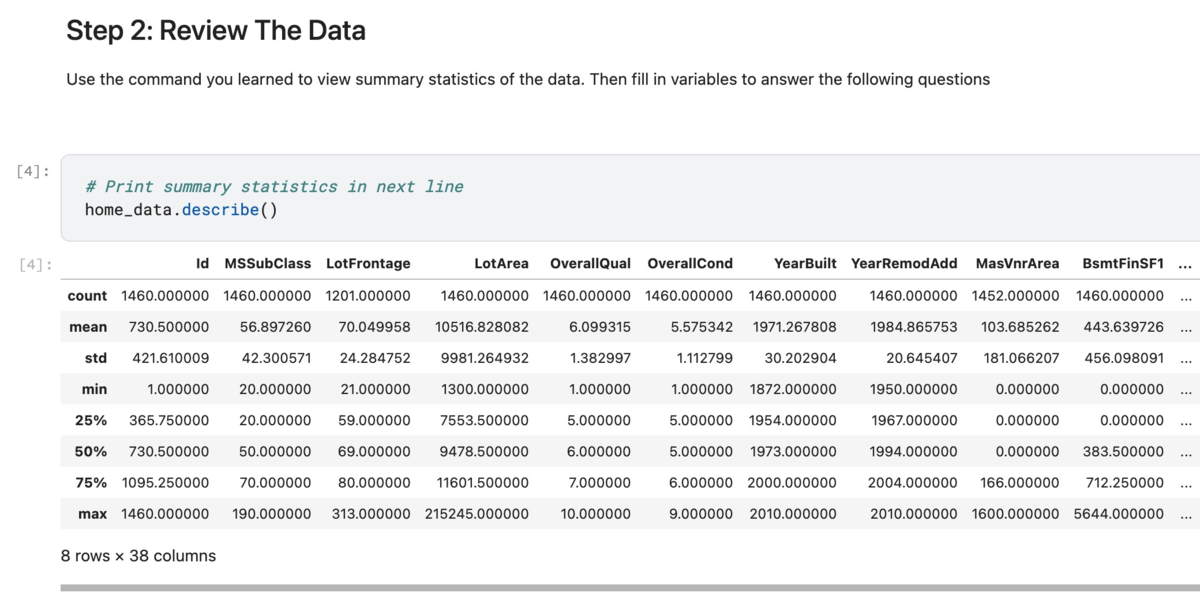
さっそく Pandas を使って「住宅データ」 を確認していく.特に複雑な内容はなく,DataFrame の describe() 関数を使って統計量を確認している.データを観察することは重要!👀
3. Your First Machine Learning Model 🌴
次に「決定木」 を使ってモデルを構築する.まずは「住宅データ」 の中から今回使う説明変数(特徴量)を決める.
説明変数
LotArea
YearBuilt
1stFlrSF
2ndFlrSF
FullBath
BedroomAbvGr
TotRmsAbvGrd
目的変数
実装としては scikit-learn の DecisionTreeRegressor クラスを使う.今回は結果に統一性を持たせるために random_state パラメータも指定している.以下は重要なコードを抜粋して載せている.
import pandas as pd
from sklearn.tree import DecisionTreeRegressor
iowa_file_path = '../input/home-data-for-ml-course/train.csv'
home_data = pd.read_csv(iowa_file_path)
feature_names = [ 'LotArea' , 'YearBuilt' , '1stFlrSF' , '2ndFlrSF' , 'FullBath' , 'BedroomAbvGr' , 'TotRmsAbvGrd' ]
X = home_data[feature_names]
y = home_data.SalePrice
iowa_model = DecisionTreeRegressor(random_state=1 )
iowa_model.fit(X, y)
predictions = iowa_model.predict(X)
実際に構築したモデルを使って予測をすると,以下のように結果を確認できる.
4. Model Validation 🌴
予測結果を評価するために,次は「平均絶対誤差 : MAE (Mean Absolute Error)」 を使う.MAE は名前の通り「正解と予測の差の平均値」 を計算する.まずは scikit-learn で train_test_split() 関数を使って「学習用データと正解ラベル」 と「テスト用データと正解ラベル」 に分割する.そして MAE も mean_absolute_error() 関数を使えば良く,簡単に予測結果を評価できるようになった.とは言え 29652.931506849316 という平均絶対誤差は大きく,モデルを改善する必要がある.
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state=1 )
val_predictions = iowa_model.predict(val_X)
val_mae = mean_absolute_error(val_predictions, val_y)
print (val_mae)
5. Underfitting and Overfitting 🌴
そこで「Underfitting(過少適合)」 と「 Overfitting(過剰適合/過学習)」 という概念を考慮しながら,「決定木」 の最適な「リーフノード(葉)」 を模索していく.以下のように 5 から 500 までの組み合わせを検証して,今回は 100 が最適だと判断できた.以下は重要なコードを抜粋して載せている.
def get_mae (max_leaf_nodes, train_X, val_X, train_y, val_y):
model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0 )
model.fit(train_X, train_y)
preds_val = model.predict(val_X)
mae = mean_absolute_error(val_y, preds_val)
return (mae)
candidate_max_leaf_nodes = [5 , 25 , 50 , 100 , 250 , 500 ]
scores = {leaf_size: get_mae(leaf_size, train_X, val_X, train_y, val_y) for leaf_size in candidate_max_leaf_nodes}
print (scores)
best_tree_size = min (scores, key=scores.get)
print (best_tree_size)
6. Random Forests 🌴
モデルを改善するために「決定木」 よりも優れている「ランダムフォレスト」 を使ってモデルを作り直す.scikit-learn で RandomForestRegressor クラスを使えば,簡単に「ランダムフォレスト」 を実装できる.実際に予測結果を評価すると,平均絶対誤差は 21946.238703196348 となった.少し改善することができた.
from sklearn.ensemble import RandomForestRegressor
rf_model = RandomForestRegressor()
rf_model.fit(train_X, train_y)
rf_val_predictions = rf_model.predict(val_X)
rf_val_mae = mean_absolute_error(rf_val_predictions, val_y)
print ("Validation MAE for Random Forest Model: {}" .format(rf_val_mae))
なお,コースには「ランダムフォレスト」 の詳細解説までは載っていないため,関連資料を組み合わせるとより理解度が高まると思う.今回は「機械学習図鑑」 を併読した.
7. Machine Learning Competitions 🌴
よりモデルを改善するために,最後は Kaggle Competitions「Housing Prices Competition for Kaggle Learn Users」 に挑戦して!という内容だった.もう少し勉強をしたら Kaggle Competitions にも挑戦してみたい💪
www.kaggle.com
まとめ 🌴
「Kaggle Courses」 で機械学習に入門できる「Intro to Machine Learning」 コースを受講した.scikit-learn を使って「決定木(回帰)」 や「ランダムフォレスト」 で「住宅価格予測」 を体験できる.Pandas や scikit-learn の実装は「Python 3 エンジニア認定データ分析試験」 を受験したときに繰り返し学んだため,特にハマるところはなくスラスラと読めた.
kakakakakku.hatenablog.com
そして今回も受講証明書を取得できた🏆









")