
AWS Step Functions ワークフローを実装しているときに,ステートをデプロイする前にテストしたり,デプロイしたワークフローの特定のステートのみを実行したいという場面があったりする.実は AWS Step Functions の「TestState API」を使うと,ワークフローをデプロイせずに1つのステートをテストできてスムーズに実装を進められる👌
ちなみに TestState API は2023年11月末にリリースされている❗️
aws.amazon.com
docs.aws.amazon.com
AWS CLI で TestState API を試す
AWS CLI の aws stepfunctions test-state コマンドを使えば TestState API を簡単に試せる.aws stepfunctions test-state コマンドの必須オプションは大きく2つ(--definition と --role-arn)ある.--definition を指定するため,実際に AWS Step Functions ワークフローをデプロイする必要はなく,Amazon States Language (ASL) を直接指定してテストできる👌
awscli.amazonaws.com
1. Lambda Invoke を試す 🧩
実際に存在する AWS Lambda 関数を呼び出すステートを JSON で定義する📝
{
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"OutputPath": "$.Payload",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:ap-northeast-1:000000000000:function:xxxxxxx:$LATEST"
},
"End": true
}
ステートのイメージは以下のような感じ.
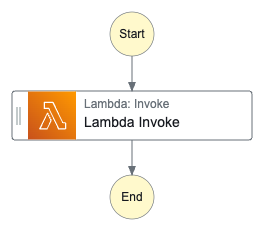
そしてコマンドを実行すると指定したワークフロー定義から AWS Lambda 関数を呼び出せた👏
$ aws stepfunctions test-state \
--definition file://state.json \
--role-arn arn:aws:iam::000000000000:role/xxxxx \
--input '{ "key1": "value1", "key2": "value2" }'
{
"output": "{\"statusCode\":200,\"body\":\"\\\"Hello from Lambda!\\\"\"}",
"status": "SUCCEEDED"
}
2. S3 PutObject を試す 🧩
次に AWS Step Functions の「SDK 統合」を使って,実際に存在する Amazon S3 バケットにオブジェクトを保存するステートを JSON で定義する📝
{
"Type": "Task",
"Resource": "arn:aws:states:::aws-sdk:s3:putObject",
"Parameters": {
"Body.$": "$.body",
"Bucket": "xxxxxxxxxx",
"Key": "aws-stepfunctions-test-state.txt"
},
"End": true
}
ステートのイメージは以下のような感じ.
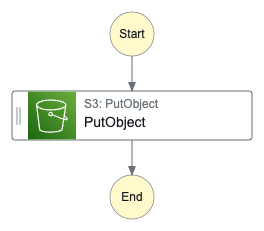
そしてコマンドを実行すると指定したワークフロー定義から Amazon S3 バケットにオブジェクトを保存できた👏
$ aws stepfunctions test-state \
--definition file://state.json \
--role-arn arn:aws:iam::000000000000:role/xxxxx \
--input '{ "body": "hello!" }'
{
"output": "{\"ETag\":\"\\\"1092c22d20edf737ded7bfb149dd8c9e\\\"\",\"ServerSideEncryption\":\"AES256\"}",
"status": "SUCCEEDED"
}
3. Choice (NumericEquals) を試す 🧩
今度は AWS Step Functions の Choiceドキュメントに載っている NumericEquals のサンプルを参考に分岐のあるステートを JSON で定義する📝
{
"Type": "Choice",
"Choices": [
{
"Variable": "$.foo",
"NumericEquals": 1,
"Next": "FirstMatchState"
}
],
"Default": "Success"
}
ステートのイメージは以下のような感じ.
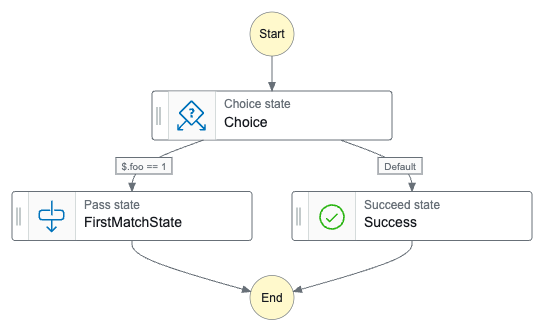
分岐をテストするために { "foo": 1 } と { "foo": 100 } を指定してコマンドを実行すると,期待した nextState になっていることを確認できた👏
$ aws stepfunctions test-state \
--definition file://state.json \
--role-arn arn:aws:iam::000000000000:role/xxxxx \
--input '{ "foo": 1 }'
{
"output": "{ \"foo\": 1 }",
"nextState": "FirstMatchState",
"status": "SUCCEEDED"
}
$ aws stepfunctions test-state \
--definition file://state.json \
--role-arn arn:aws:iam::000000000000:role/xxxxx \
--input '{ "foo": 100 }'
{
"output": "{ \"foo\": 100 }",
"nextState": "Success",
"status": "SUCCEEDED"
}
4. Choice (IsNull) を試す 🧩
もう一つ AWS Step Functions の Choiceドキュメントに載っている IsNull のサンプルを参考に分岐のあるステートを JSON で定義する📝
{
"Type": "Choice",
"Choices": [
{
"Variable": "$.possiblyNullValue",
"IsNull": true,
"Next": "Fail"
}
],
"Default": "Success"
}
ステートのイメージは以下のような感じ.
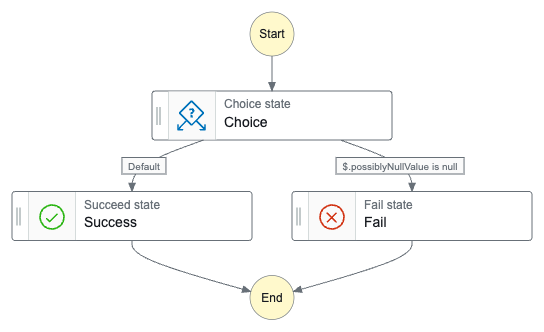
分岐をテストするために { "possiblyNullValue": 12345 } と {} を指定してコマンドを実行すると,期待した nextState になっていることを確認できた👏
$ aws stepfunctions test-state \
--definition file://state.json \
--role-arn arn:aws:iam::000000000000:role/xxxxx \
--input '{ "possiblyNullValue": 12345 }'
{
"output": "{ \"possiblyNullValue\": 12345 }",
"nextState": "Success",
"status": "SUCCEEDED"
}
$ aws stepfunctions test-state \
--definition file://state.json \
--role-arn arn:aws:iam::000000000000:role/xxxxx \
--input '{}'
{
"error": "States.Runtime",
"cause": "Invalid path '$.possiblyNullValue': The choice state's condition path references an invalid value.",
"status": "FAILED"
}
マネジメントコンソールで TestState API を試す
TestState API は AWS Step Functions のマネジメントコンソールでも使える❗️
デプロイ前のワークフローであれば AWS Step Functions Workflow Studio で テスト状態 というボタンを押す.さらにデプロイして実行した AWS Step Functions ワークフローに対しても,特定のステートを選択して テスト状態 というボタンを押せば,インプットを変更して実行できる👌個人的には テスト状態 という日本語訳が微妙で気付きにくいように思う💨
デプロイして実行した AWS Step Functions ワークフローのトラブルシューティングに TestState API を使うことが多く,複雑なワークフローを開発しているときに特に便利だな〜と感じる❗️
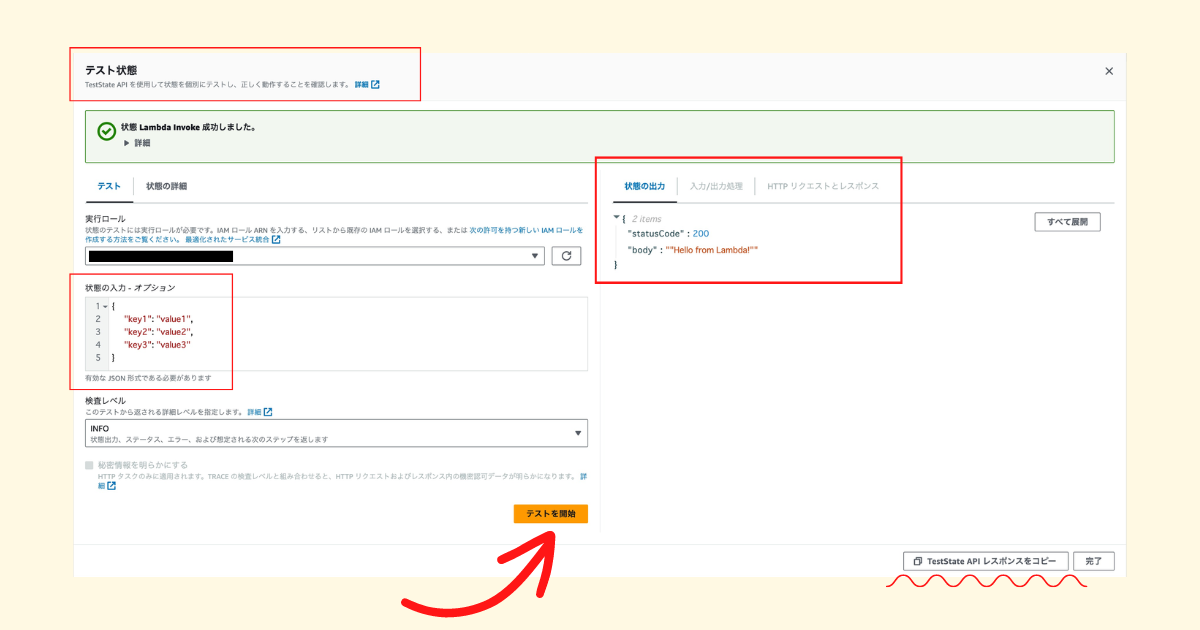
TestState API を自動テストに活用する
AWS Compute Blog のブログ記事 Accelerating workflow development with the TestState API in AWS Step Functions を読んでいたら,Jest から TestState API を実行してレスポンスの nextState と status を確認する自動テストに活用する例が載っていて参考になった📝
aws.amazon.com




")


