Kaggle が公開している「Kaggle Courses」で「Intermediate Machine Learning」コースを受講した.Kaggle のコンペティション「Housing Prices Competition for Kaggle Learn Users(住宅価格予測)」をテーマに試行錯誤をして,実際にモデルを登録することもできる.アルゴリズムとしては「ランダムフォレスト」と「XGBoost」を使う.アジェンダを見るとわかる通り,データセットの前処理からモデルの構築評価まで幅広く体験できる.
なお,前提コースである「Pandas」と「Intro to Machine Learning」は既に受講していて,以下にまとめてある.
アジェンダ 🏠
「Intermediate Machine Learning」コースには「計7種類」のレッスン(ドキュメントと演習)がある.
- Introduction
- Missing Values
- Categorical Variables
- Pipelines
- Cross-Validation
- XGBoost
- Data Leakage
住宅価格予測 🏠
1460 件のデータセットに 80 個の特徴量を含んでいる.その中から今回は 7 個の特徴量を使う.このあたりは前提コース「Intro to Machine Learning」と同じ.そして,特徴量の中に予測する SalePrice(住宅価格) も含まれていることから「教師あり学習(回帰)」と言える.
X_full.shape # (1460, 80) X.shape # (1460, 7) X.columns # Index(['LotArea', 'YearBuilt', '1stFlrSF', '2ndFlrSF', 'FullBath', 'BedroomAbvGr', 'TotRmsAbvGrd'], dtype='object')
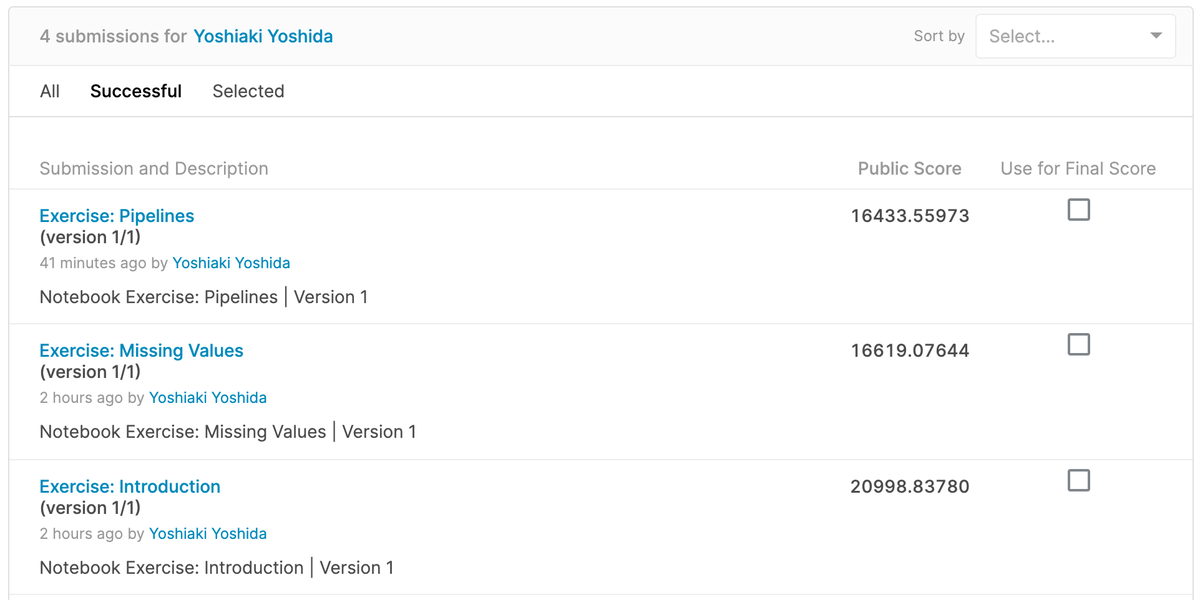
まず 1. Introduction と 2. Missing Values と 3. Categorical Variables と 4. Pipelines では,scikit-learn の RandomForestRegressor を使って「ランダムフォレスト」でモデルを構築する.以下のように適当にパラメータを設定して比較したり(今回は model_3 の平均絶対誤差 MAE が1番低かった👌),欠損値を考慮したり,カテゴリ変数をエンコーディングしたり,一歩一歩モデル精度を向上させていく.また scikit-learn の Pipeline を使って,コード実装を改善する.
model_1 = RandomForestRegressor(n_estimators=50, random_state=0) model_2 = RandomForestRegressor(n_estimators=100, random_state=0) model_3 = RandomForestRegressor(n_estimators=100, criterion='mae', random_state=0) model_4 = RandomForestRegressor(n_estimators=200, min_samples_split=20, random_state=0) model_5 = RandomForestRegressor(n_estimators=100, max_depth=7, random_state=0)
実際に評価をしながら進めるため,今回は欠損値を平均値で埋めるよりも特徴量を削除した方がパフォーマンスが良いなど,予想とは違う気付きもあって良かった.
- Missing Values(欠損値)
- [1] A Simple Option: Drop Columns with Missing Values(単純に特徴量を削除する)
- [2] A Better Option: Imputation(より良く平均値などで埋める)
- [3] An Extension To Imputation(値を埋めつつ欠損値の有無を表現する新しい特徴量を追加する)
- Categorical Variables(カテゴリ変数)
- [1] Drop Categorical Variables(カテゴリ変数を削除する)
- [2] Ordinal Encoding(順序エンコーディング)
- [3] One-Hot Encoding(ワンホットエンコーディング)
実際に Kaggle コンペティションにモデルを登録して,Leaderboard で順位が上がっていくことも確認する🏆
交差検証 🏠
5. Cross-Validation では,scikit-learn の cross_val_score() を使って「交差検証」を行う.分割数 cv を 3 や 5 に設定しながら最終的な平均値を確認する.
そして「ランダムフォレスト」に設定するパラメータ n_estimators の最善値を探す.今回は n_estimators = 50, 100, 150, 200, 250, 300, 350, 400 で比較して,結果的として 200 のパフォーマンスが1番良かった.

XGBoost 🏠
ここまでは「ランダムフォレスト(アンサンブル学習)」を使ってきたけど,次は「XGBoost(勾配ブースティング)」を適用する.以下のようにパラメータを変えて比較をするけど,重要なのはアルゴリズムを変えることも考えながらコンペティションに参加するという点になる.
my_model_1 = XGBRegressor(random_state=0) # Mean Absolute Error: 17662.736729452055 my_model_2 = XGBRegressor(n_estimators=1000, learning_rate=0.05) # Mean Absolute Error: 16688.691513270547 my_model_3 = XGBRegressor(n_estimators=1) # Mean Absolute Error: 127895.0828807256
Data Leakage 🏠
7. Data Leakage では,モデルに対する考察として「Data Leakage(データ漏洩)」を学ぶ.「Data Leakage」とは,トレーニングデータセットにターゲットに関する「含まれていはいけないデータが含まれていること」と言える.よって,モデルの検証時にはパフォーマンスが高くなり,本番環境にデプロイするとパフォーマンスが低くなってしまう.「Data Leakage」として,具体的には以下の2種類が載っていた.
- Target leakage(ターゲット漏洩)
- 例 : 肺炎予測をするときに「抗生物質を服用しているか」という特徴量を使ってしまう
- 本来は「肺炎である」と診断されてから処方されるため,将来の予測には使えない
- 例 : 肺炎予測をするときに「抗生物質を服用しているか」という特徴量を使ってしまう
- Train-Test Contamination(トレインテスト汚染)
- 例 : データセットを前処理する場合に欠損値を平均値などで埋める場合に検証データの精度が高くなってしまう
- 検証データを除外して前処理をする
- scikit-learn の
train_test_split()から Train-Test という名前になっている
- 例 : データセットを前処理する場合に欠損値を平均値などで埋める場合に検証データの精度が高くなってしまう
まとめ 🏠
「Kaggle Courses」で「Intermediate Machine Learning」コースを受講した.Kaggle のコンペティション「Housing Prices Competition for Kaggle Learn Users(住宅価格予測)」に参加することもできて,一般的な機械学習ワークフローを体験することができた.とても良かった👏
次は「Feature Engineering」コースと「Machine Learning Explainability」コースに進もうと思う.