scikit-learn の Pipeline を使うと,データセットの前処理や機械学習アルゴリズムなどを「1つのオブジェクトに」まとめることができる.
前回の記事で紹介した「Kaggle Courses」の「Intermediate Machine Learning」コースでも使われていたこともあり,もう少しドキュメントを読みながら試していく.
Pipeline に入門する
「Kaggle Courses」のコースを参考にサンプルコードを書くと,以下のようになる(重要なコードのみを抜粋している).Pipeline を使わずにコードを書くと SimpleImputer や OneHotEncoder や RandomForestRegressor など,それぞれで fit() や fit_transform() を実行する必要があるため,コード量を減らしつつ,可読性が高く実装できる.イイネ👏
from sklearn.ensemble import RandomForestRegressor from sklearn.impute import SimpleImputer from sklearn.pipeline import Pipeline from sklearn.preprocessing import OneHotEncoder X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, test_size=0.2, random_state=0) pipeline = Pipeline( steps=[ ('imputer', SimpleImputer(strategy='most_frequent')), ('encoder', OneHotEncoder(handle_unknown='ignore')), ('model', RandomForestRegressor(n_estimators=50, random_state=0)) ] ) pipeline.fit(X_train, y_train) pipeline.predict(X_test)
また Pipeline に verbose=True パラメータを追加すると fit() を実行しながら以下のように進捗を表示することもできる.
pipeline = Pipeline(
steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OneHotEncoder(handle_unknown='ignore')),
('model', RandomForestRegressor(n_estimators=50, random_state=0))
],
verbose=True
)
# [Pipeline] ........... (step 1 of 3) Processing imputer, total= 0.1s
# [Pipeline] ........... (step 2 of 3) Processing encoder, total= 0.1s
# [Pipeline] ............. (step 3 of 3) Processing model, total= 10.1s
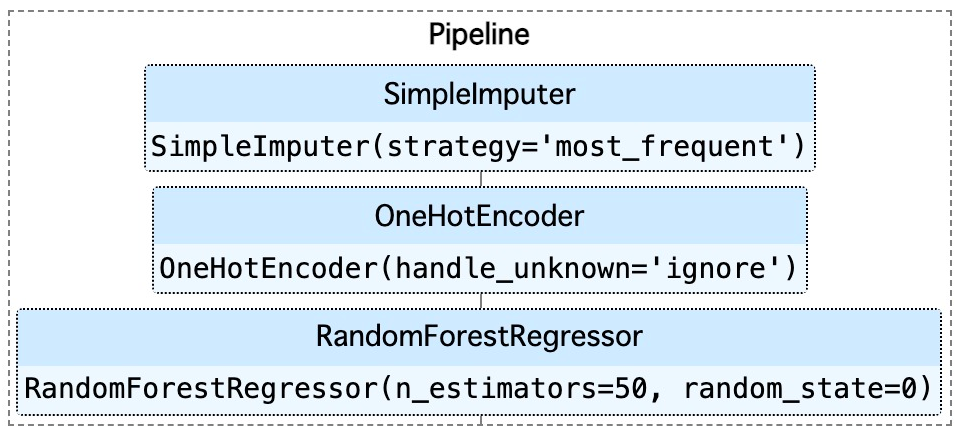
そして,以下のドキュメントを参考に set_config() を使って「ダイアグラム表示」を有効化すると,以下のように Pipeline 構成を図として表示できる.実際には枠をクリックすることができて,パラメータを表示したり,非表示にしたりできる.
from sklearn import set_config set_config(display='diagram') pipeline
Pipeline で前処理をカテゴライズする
さらに Pipeline の中で前処理をカテゴライズすることもできる.例えば,以下のように numeric_preprocessor(量的変数) と categorical_preprocessor(カテゴリ変数) としてまとめている(重要なコードのみを抜粋している).最終的には make_pipeline() を使って RandomForestRegressor とまとめている.今回のサンプルコード以上に前処理などが多いときに効果が出そう.
from sklearn.compose import ColumnTransformer from sklearn.ensemble import RandomForestRegressor from sklearn.impute import SimpleImputer from sklearn.pipeline import make_pipeline from sklearn.pipeline import Pipeline from sklearn.preprocessing import OneHotEncoder, StandardScaler numeric_preprocessor = Pipeline( steps=[ ('imputer', SimpleImputer(strategy='most_frequent')), ('scaler', StandardScaler()), ] ) categorical_preprocessor = Pipeline( steps=[ ('onehot', OneHotEncoder(handle_unknown='ignore')), ] ) pipeline = make_pipeline( ColumnTransformer( [ ('numerical', numeric_preprocessor, numerical_cols), ('categorical', categorical_preprocessor, categorical_cols) ] ), RandomForestRegressor(n_estimators=50, random_state=0) )
同じく set_config() を使って「ダイアグラム表示」を有効化すると,より整理された Pipeline 構成を表示することができた.
from sklearn import set_config set_config(display='diagram') pipeline

まとめ
scikit-learn の Pipeline を使うと,データセットの前処理や機械学習アルゴリズムなどを「1つのオブジェクトに」まとめることができる.今回はシンプルな Pipeline 構成とカテゴライズをした構成を紹介した.ドキュメントを読むと,他にも GridSearchCV と組み合わせてハイパーパラメータを探索することもできて,便利だった.