Pandas で groupby() 関数を使うと,データセットをグループ化して集計できる.さらに Grouper オブジェクトと組み合わせると,より高機能なグループ化を実現できる.今回は groupby() 関数と Grouper オブジェクトを組み合わせて「時系列データの集計」を試す.最後に関連する resample() 関数も試す.
データセット 🪢
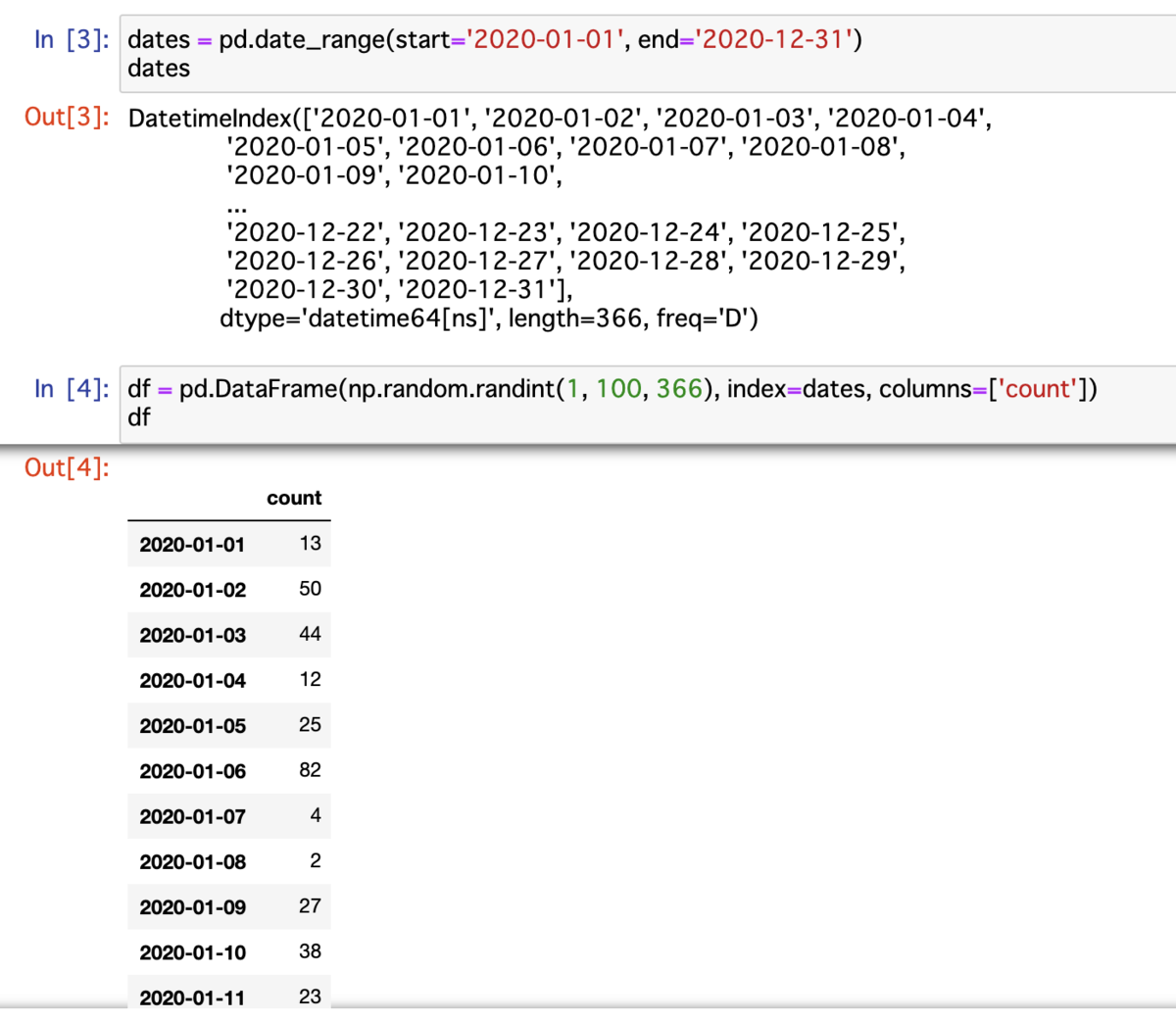
今回使うサンプルデータセットを準備する.まず,Pandas の date_range() 関数を使って 2020/1/1 ~ 2020/12/31 の範囲で1年間の DatetimeIndex を作る.そして DatetimeIndex をインデックス値とした DataFrame を作る.今回は count カラムとして 1 ~ 99 の範囲で乱数を含めておく.乱数は Numpy の random.randint() 関数を使う.結果的に以下のような DataFrame になる.
dates = pd.date_range(start='2020-01-01', end='2020-12-31') dates # DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-04', # '2020-01-05', '2020-01-06', '2020-01-07', '2020-01-08', # '2020-01-09', '2020-01-10', # ... # '2020-12-22', '2020-12-23', '2020-12-24', '2020-12-25', # '2020-12-26', '2020-12-27', '2020-12-28', '2020-12-29', # '2020-12-30', '2020-12-31'], # dtype='datetime64[ns]', length=366, freq='D') df = pd.DataFrame(np.random.randint(1, 100, 366), index=dates, columns=['count']) df # 2020-01-01 13 # 2020-01-02 50 # 2020-01-03 44 # 2020-01-04 12 # 2020-01-05 25 # 2020-01-06 82 # 2020-01-07 4 # 2020-01-08 2 # 2020-01-09 27 # 2020-01-10 38 # (中略)
groupby() 関数と Grouper オブジェクトを組み合わせる 🪢
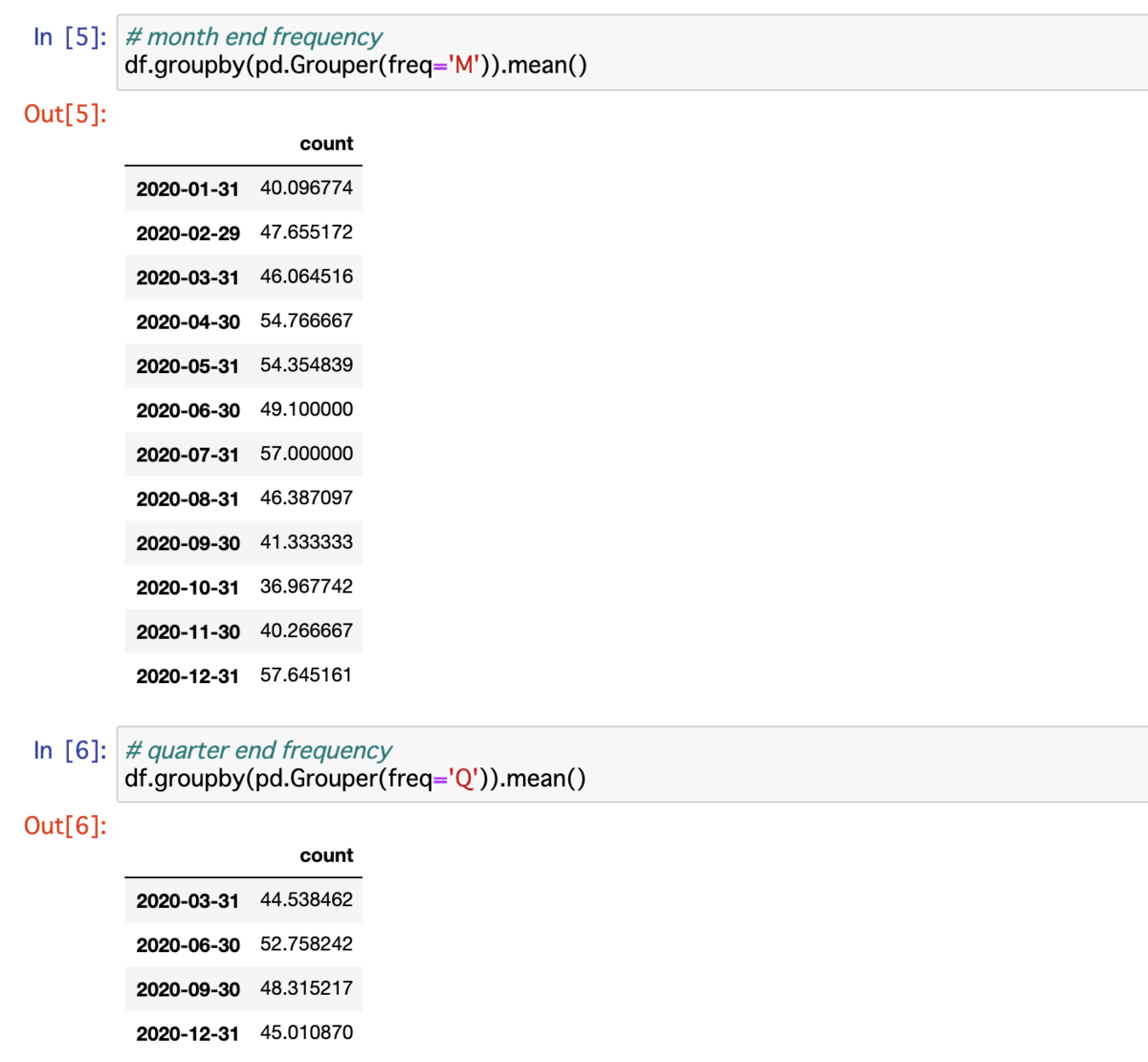
以下のように DataFrame に対して groupby() 関数と Grouper オブジェクトを組み合わせる.まず pd.Grouper(freq='M') と pd.Grouper(freq='Q') を試す.M は「月末集計」で Q は「四半期集計」となる.そして今回は mean() 関数を使って「平均値」を取得する.このように Grouper オブジェクト を使うと簡単に「時系列データの集計」を実現できる.
M: month end frequencyQ: quarter end frequency
# month end frequency df.groupby(pd.Grouper(freq='M')).mean() # 2020-01-31 40.096774 # 2020-02-29 47.655172 # 2020-03-31 46.064516 # 2020-04-30 54.766667 # 2020-05-31 54.354839 # 2020-06-30 49.100000 # 2020-07-31 57.000000 # 2020-08-31 46.387097 # 2020-09-30 41.333333 # 2020-10-31 36.967742 # 2020-11-30 40.266667 # 2020-12-31 57.645161 # quarter end frequency df.groupby(pd.Grouper(freq='Q')).mean() # 2020-03-31 44.538462 # 2020-06-30 52.758242 # 2020-09-30 48.315217 # 2020-12-31 45.010870
また以下のドキュメント(DateOffset objects → Offset aliases と Anchored offsets)を読むと freq に指定できる識別子は他にも多くある.代表的な例を以下に抜粋した.
W: weekly frequencySM: semi-month end frequency (15th and end of month)H: hourly frequencyW-SUN: weekly frequency (Sundays). Same as ‘W’W-MON: weekly frequency (Mondays)W-TUE: weekly frequency (Tuesdays)- etc
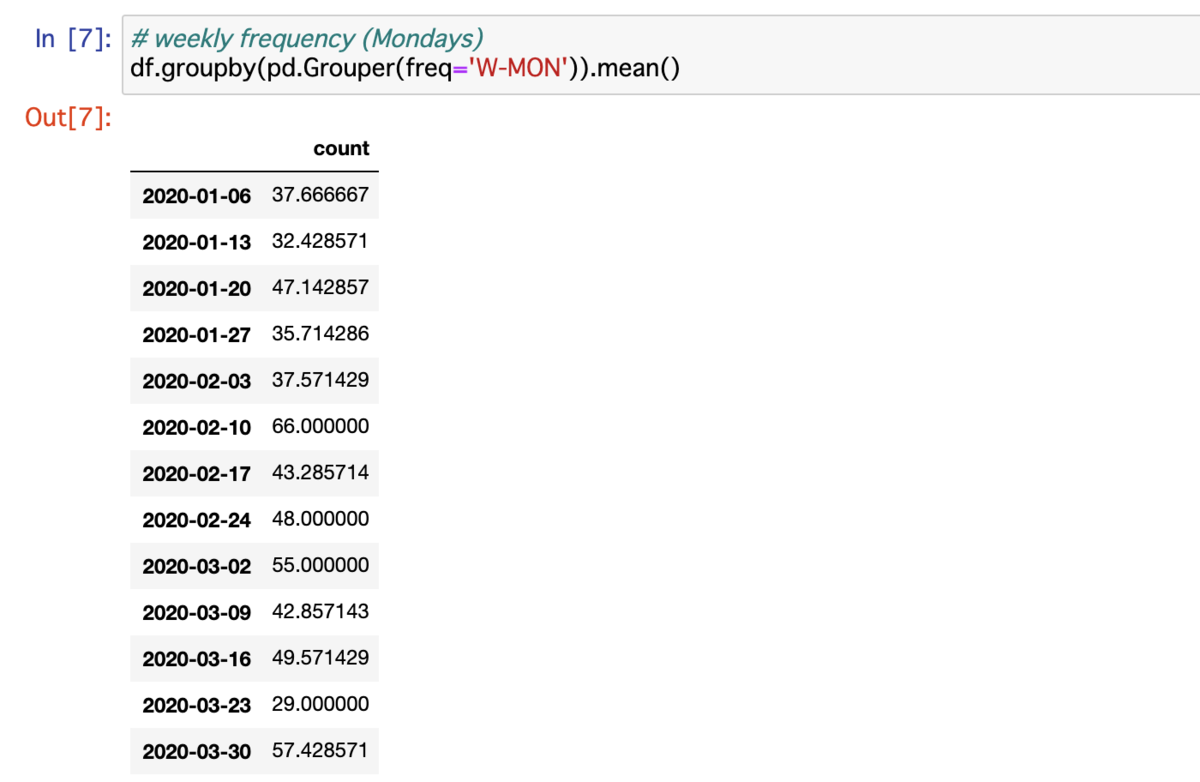
例えば pd.Grouper(freq='W-MON') を指定すると「週次集計」で軸にする「曜日(ここでは月曜日)」を指定できる.デフォルトでは W は W-SUN となる.正確に値を計算すると 2020/1/13 (月) の 32.428571 は 2020/1/7 (火) ~ 2020/1/13 (月) の期間での平均値となるため,計算式としては (4 + 2 + 27 + 38 + 23 + 62 + 71) / 7 = 32.428571 として確認できる.
# weekly frequency (Mondays) df.groupby(pd.Grouper(freq='W-MON')).mean() # 2020-01-06 37.666667 # 2020-01-13 32.428571 # 2020-01-20 47.142857 # 2020-01-27 35.714286 # 2020-02-03 37.571429 # 2020-02-10 66.000000 # 2020-02-17 43.285714 # 2020-02-24 48.000000 # (中略)
Grouper オブジェクトの key パラメータ 🪢
デフォルトの挙動では DataFrame のインデックス値が DatetimeIndex や TimedeltaIndex である必要があるため,それ以外の DataFrame だと TypeError: Only valid with DatetimeIndex, TimedeltaIndex or PeriodIndex, but got an instance of 'RangeIndex' というエラーが出る.その場合は Grouper オブジェクトの key パラメータを使ってカラムを指定する.
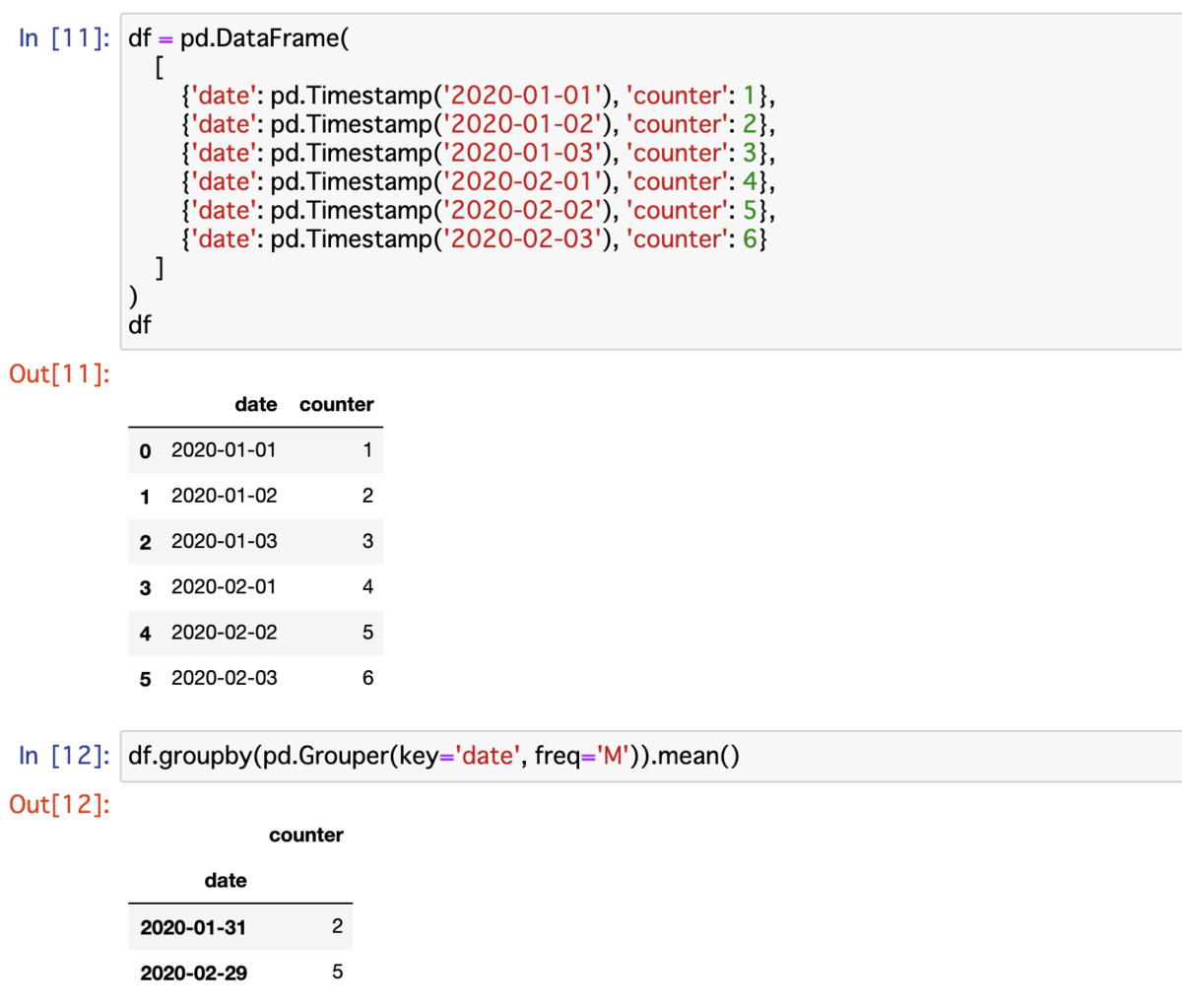
動作確認をするために以下のようなサンプルデータセットを準備する.DataFrame のインデックス値は 0,1,2 ... という数値とし,date カラムに日付を含める.そして pd.Grouper(key='date', freq='M') のように key パラメータを指定すると,期待した平均値となった.
df = pd.DataFrame(
[
{'date': pd.Timestamp('2020-01-01'), 'counter': 1},
{'date': pd.Timestamp('2020-01-02'), 'counter': 2},
{'date': pd.Timestamp('2020-01-03'), 'counter': 3},
{'date': pd.Timestamp('2020-02-01'), 'counter': 4},
{'date': pd.Timestamp('2020-02-02'), 'counter': 5},
{'date': pd.Timestamp('2020-02-03'), 'counter': 6}
]
)
df
# 0 2020-01-01 1
# 1 2020-01-02 2
# 2 2020-01-03 3
# 3 2020-02-01 4
# 4 2020-02-02 5
# 5 2020-02-03 6
df.groupby(pd.Grouper(key='date', freq='M')).mean()
# 2020-01-31 2
# 2020-02-29 5
関連する resample() 関数も試す 🪢
Pandas のドキュメントを読むと,resample() 関数を使った「時系列データの集計」の例も載っていた.最近読んだ「Pandas ライブラリ活用入門」にも resample() 関数の例が載っていた.
- pandas.DataFrame.resample — pandas 1.2.4 documentation
- pandas.core.groupby.DataFrameGroupBy.resample — pandas 1.2.4 documentation
- Group by: split-apply-combine — pandas 1.2.4 documentation

Pythonデータ分析/機械学習のための基本コーディング! pandasライブラリ活用入門 impress top gearシリーズ
- 作者:Daniel Y. Chen,吉川 邦夫,福島 真太朗
- 発売日: 2019/02/22
- メディア: Kindle版
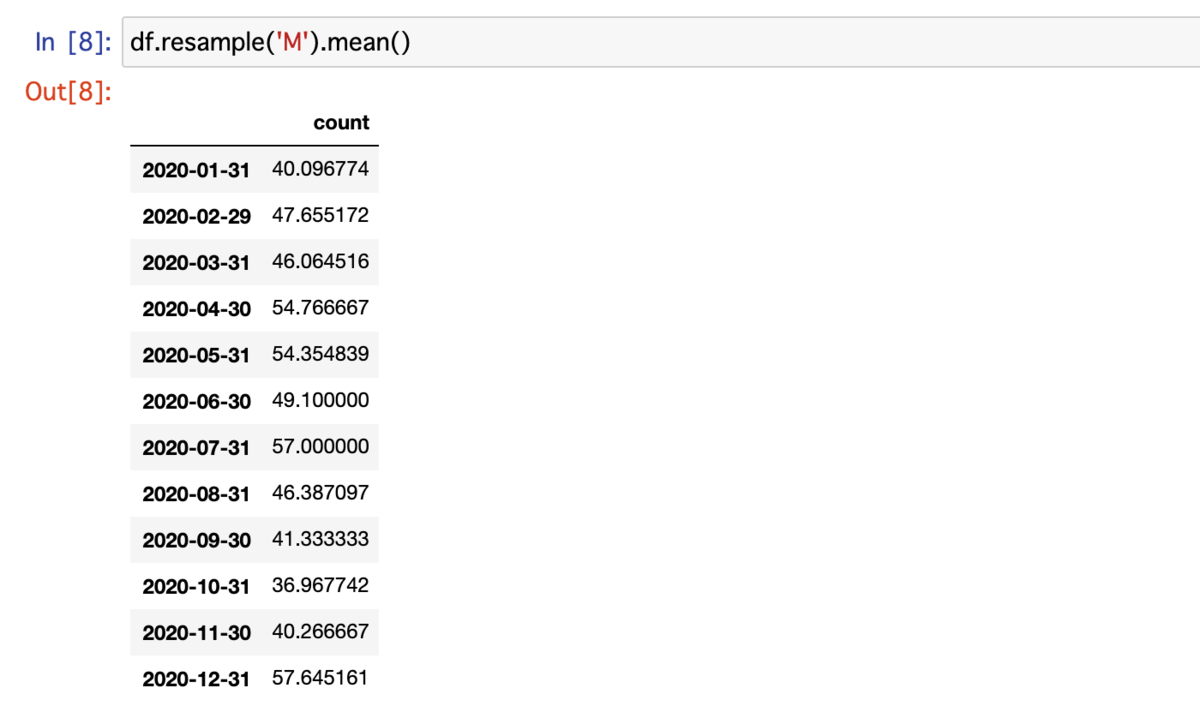
実際に試したところ,Grouper オブジェクトと同じような集計ができた.例えば,以下は同じデータセットに対して「月末集計」をした結果で,平均値は完全に一致していた.また on パラメータを使ってカラムを指定することもできる.今回試した範囲だと Grouper オブジェクトと resample() 関数の機能面での差は確認できなかった.どう使い分けるんだろう?
df.resample('M').mean() # 2020-01-31 40.096774 # 2020-02-29 47.655172 # 2020-03-31 46.064516 # 2020-04-30 54.766667 # 2020-05-31 54.354839 # 2020-06-30 49.100000 # 2020-07-31 57.000000 # 2020-08-31 46.387097 # 2020-09-30 41.333333 # 2020-10-31 36.967742 # 2020-11-30 40.266667 # 2020-12-31 57.645161 df.resample('Q').mean() df.resample('W-MON').mean() df.resample(on='date', rule='M').mean()
まとめ 🪢
今回は Pandas で groupby() 関数と Grouper オブジェクトを組み合わせて「時系列データの集計」を試した.「月末集計」や「四半期集計」そして「週集計」など高機能なグループ化を実現できる.引き続き気になった機能はどんどん試していくぞー👏