Kaggle が公開している「Kaggle Courses」で「Feature Engineering」コースを受講した.機械学習モデルを構築するときに重要になる「特徴量エンジニアリング」を多岐にわたる観点から学べる.「特徴量エンジニアリング」の目標は「データセットを目の前の問題に対してより適切な形にすること」であるとコースでは紹介されていて,より具体的には以下となる.
- モデルの予測パフォーマンスを向上させるため
- 計算またはデータのニーズを削減するため
- 結果の解釈可能性を向上させるため
アジェンダ ✏️
「Feature Engineering」コースは「計6種類」のレッスン(ドキュメント)と「計5種類」のレッスン(演習)から構成されている.「相互情報量」や「K-means」や「主成分分析 (PCA)」や「Target Encoding」など,多岐にわたる.
- What Is Feature Engineering
- Mutual Information
- Creating Features
- Clustering With K-Means
- Principal Component Analysis
- Target Encoding
また「Feature Engineering」コースの前提になる「Intermediate Machine Learning」コースは既に受講していて,以下にまとめてある.
相互情報量 ✏️
まず,特徴量とラベルの関係を知るために「相互情報量 (Mutual Information)」を使う.よく Pandas の corr() 関数を使って「相関係数」を算出するけど,あくまで「相関係数」は2種類のデータが「線形的な」関係性のときに使う.「相互情報量」は線形的な関係性でなくても使える.簡単に表現すると「相互情報量」とは「A が B の不確実性を低減する尺度」と言える.
そして scikit-learn の feature_selection モジュールには「相互情報量」を計算する関数として mutual_info_regression() : 回帰 と mutual_info_classif() : 分類 がある.
- sklearn.feature_selection.mutual_info_regression — scikit-learn 1.0.1 documentation
- sklearn.feature_selection.mutual_info_classif — scikit-learn 1.0.1 documentation


今回は Kaggle の住宅価格を予測する「住宅データセット」を使う.
今回は住宅価格を予測する回帰問題であるため mutual_info_regression() を使って SalePrice(住宅価格) との「相互情報量」を計算する.以下にソートした結果を表示する.結果を読み解くと OverallQual(全体的なクオリティ) や Neighborhood(地域内の場所) や GrLivArea(リビングの広さ) や YearBuilt(建設日) など,まぁ一般的に考えて重要そうな特徴量が上位になっている.なお「相互情報量」が低くても重要な特徴量はあるため,最終的には「ビジネス理解」が重要とも書いてあった.
OverallQual 0.581262 Neighborhood 0.569813 GrLivArea 0.496909 YearBuilt 0.437939 GarageArea 0.415014 TotalBsmtSF 0.390280 GarageCars 0.381467 FirstFlrSF 0.368825 BsmtQual 0.364779 KitchenQual 0.326194 ExterQual 0.322390 YearRemodAdd 0.315402 MSSubClass 0.287131 GarageFinish 0.265440 FullBath 0.251693 Foundation 0.236115 LotFrontage 0.233334 GarageType 0.226117 FireplaceQu 0.221955 SecondFlrSF 0.200658 Name: MI Scores, dtype: float64
特徴量抽出 ✏️
次に新しく特徴量を抽出する「計5種類」の手法を学ぶ,それぞれを以下に簡単にまとめる.
1. Create Mathematical Transforms(数学的変換)
例えば,GrLivArea(リビングの広さ) と LotArea(ロットサイズ)から,新しく LivLotRatio(ロット比率) を計算する.
X_1["LivLotRatio"] = df.GrLivArea / df.LotArea
2. Interaction with a Categorical(カテゴリ変数)
例えば,BldgType(住居タイプ) を One-Hot エンコーディングをする.
X_2 = pd.get_dummies(df.BldgType, prefix="Bldg")
3. Count Feature(カウント)
例えば,OpenPorchSF(オープンポーチエリア) など「Porch(建物の外壁から突き出している部分)」の総和を計算する.
X_3["PorchTypes"] = df[[ "WoodDeckSF", "OpenPorchSF", "EnclosedPorch", "Threeseasonporch", "ScreenPorch", ]].gt(0.0).sum(axis=1)
4. Break Down a Categorical Feature(カテゴリ変数を区切る)
例えば,MSSubClass(販売に関係する住居タイプ) には One_and_Half_Story_Finished_All_Ages や One_Story_1946_and_Newer_All_Styles という「カテゴリ変数」が含まれているため _ で文字列分割をした1個目(今回で言えば One)を抽出する.バリエーションを減らすために使う.
X_4["MSClass"] = df.MSSubClass.str.split("_", n=1, expand=True)[0]
5. Use a Grouped Transform(グループ化)
例えば,Neighborhood(地域内の場所) でグループ化をした GrLivArea(リビングの広さ) の中央値を特徴量にする.カテゴリ変数の値によって差が出る場合に効果のある特徴量になりそう.
X_5["MedNhbdArea"] = df.groupby("Neighborhood")["GrLivArea"].transform("median")
K-means ✏️
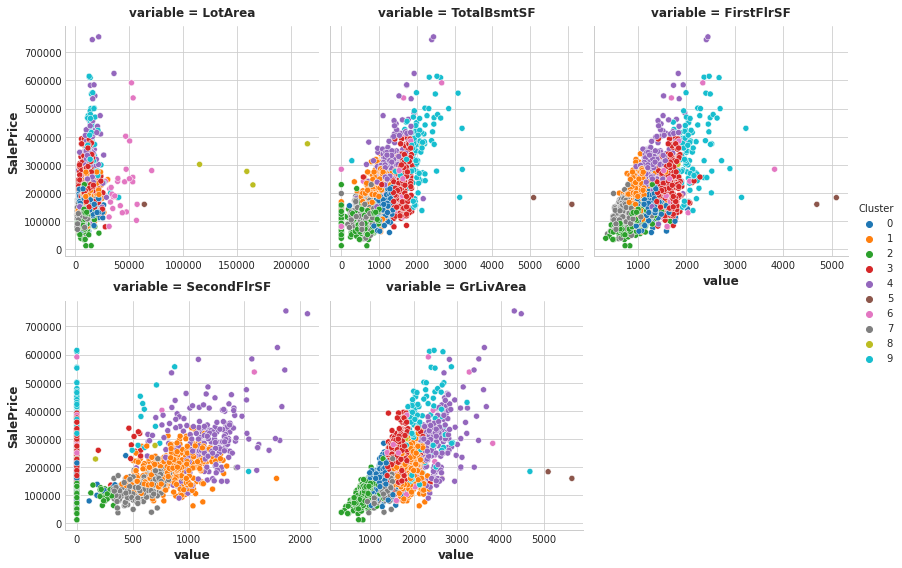
次は「教師なし学習」の代表的なアルゴリズムである「K-means」を使ってクラスタリングを行う.今回は「5種類の特徴量」から「10種類のクラスタ」を探索する.クラスタリングの結果 0 ~ 9 の値を Cluster という新しい特徴量として追加している.以下はサンプルコードを抜粋して載せている.
X = df.copy() y = X.pop("SalePrice") features = [ "LotArea", "TotalBsmtSF", "FirstFlrSF", "SecondFlrSF", "GrLivArea", ] X_scaled = X.loc[:, features] X_scaled = (X_scaled - X_scaled.mean(axis=0)) / X_scaled.std(axis=0) kmeans = KMeans(n_clusters=10, n_init=10, random_state=0) X["Cluster"] = kmeans.fit_predict(X_scaled)
また Seaborn で可視化をして,特徴量ごとにどのようにクラスタリングされているのかを確認することもできる.
主成分分析 (PCA) ✏️
「主成分分析 (PCA)」も「教師なし学習」の代表的なアルゴリズムで以下の目的で使うことができる.
- Dimensionality reduction(次元削減)
- Anomaly detection(異常検出)
- Noise reduction(ノイズリダクション)
- Decorrelation(非相関)
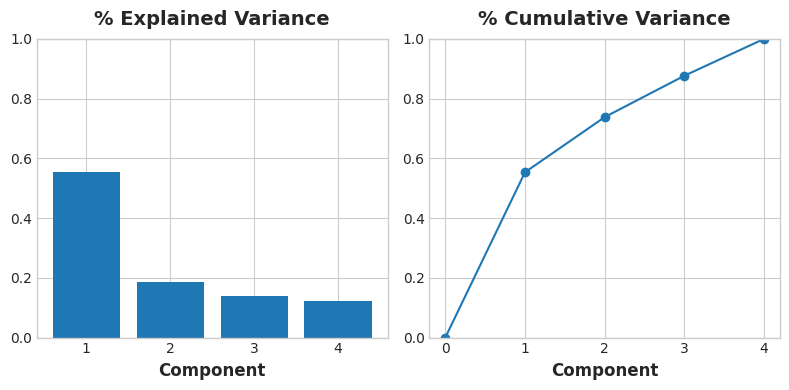
今回は以下の「4種類の特徴量」で「主成分分析 (PCA)」を実行する.必ずしも次元削減をする必要はなく,データの特性(分散など)を計算することにも使える.今回は scikit-learn の PCA で pca.fit_transform(X) を使う.
GarageArea(ガレージサイズ)YearRemodAdd(リフォーム日)TotalBsmtSF(地下室サイズ)GrLivArea(リビングの広さ)
そして,PC1 ~ PC4 という「4種類の特徴量」を抽出することができる.そして,以下のように「loading(主成分負荷量)」を表示すると,例えば,PC1 は「広さ」に着目した値になっているように考えることができる.また PC3 は GarageArea(ガレージサイズ) も YearRemodAdd(リフォーム日) も 0 に近いため「リビングと地下室の関係性」 に着目した値になっているように考えることができる.
PC1 PC2 PC3 PC4 GarageArea 0.541229 0.102375 -0.038470 0.833733 YearRemodAdd 0.427077 -0.886612 -0.049062 -0.170639 TotalBsmtSF 0.510076 0.360778 -0.666836 -0.406192 GrLivArea 0.514294 0.270700 0.742592 -0.332837
まとめ ✏️
「Kaggle Courses」で「Feature Engineering」コースを受講した.「特徴量エンジニアリング」として使うテクニックなどを多岐にわたって学べてとても良かった.そして,改めて「ビジネス理解」が重要だなと感じることができた.また「主成分分析 (PCA)」の活用に関しては個人的にまだ理解が浅いため引き続き学んでいく!



